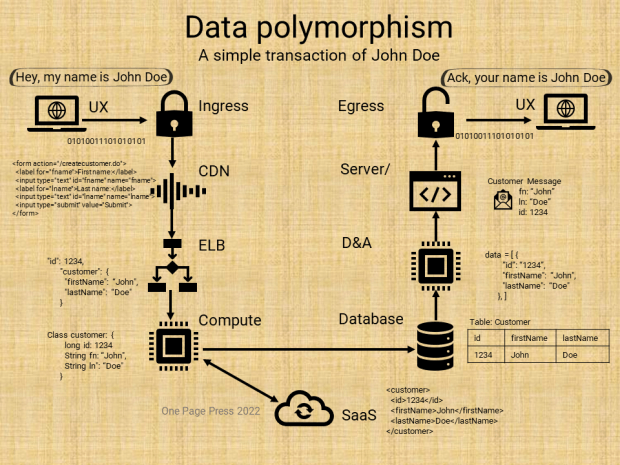
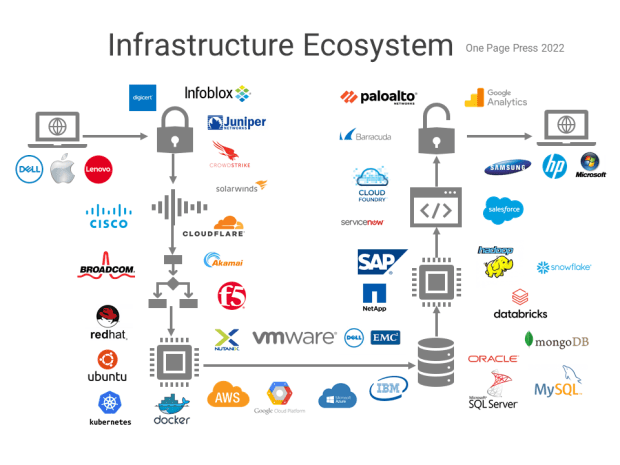
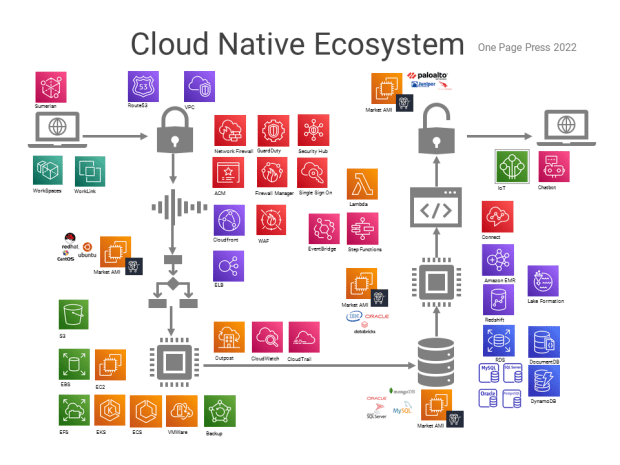
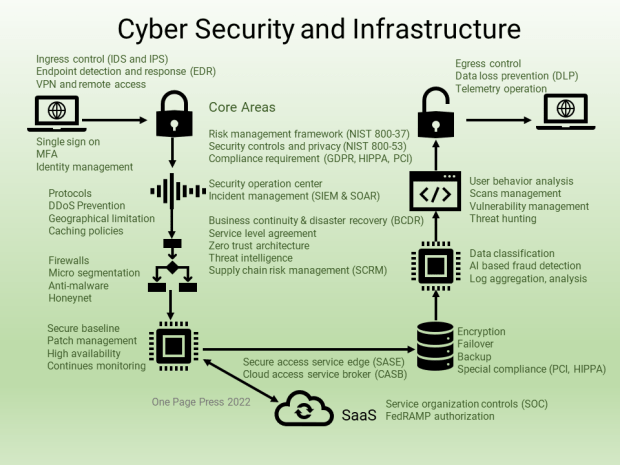
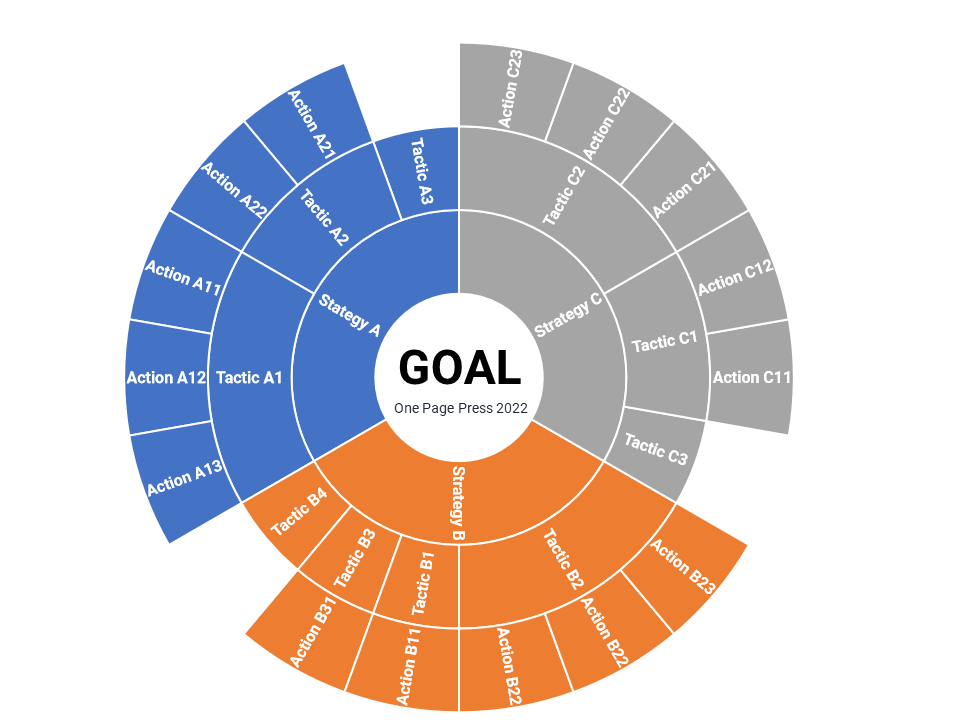
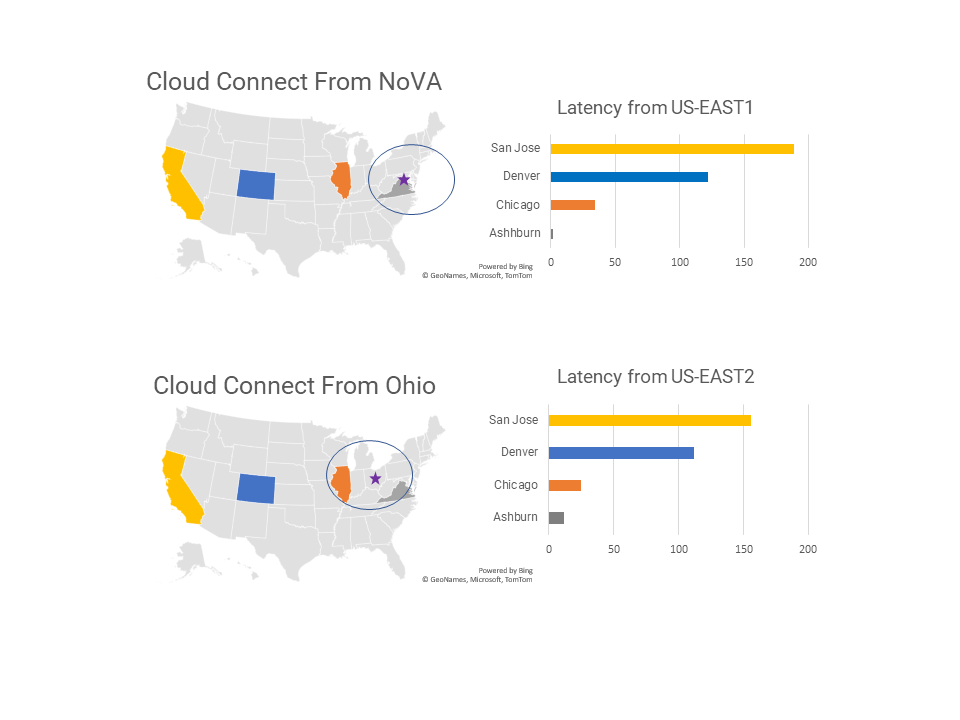
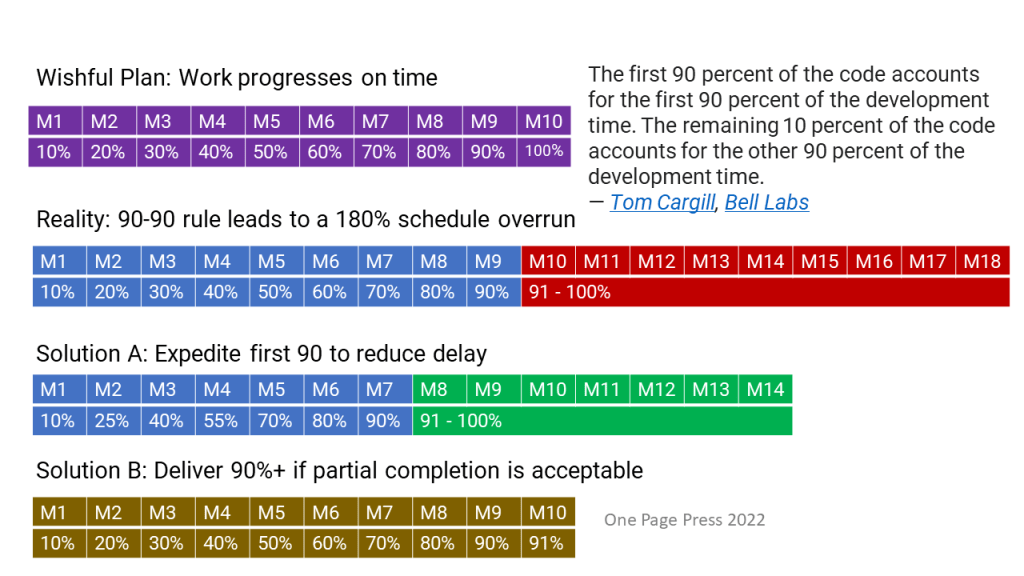
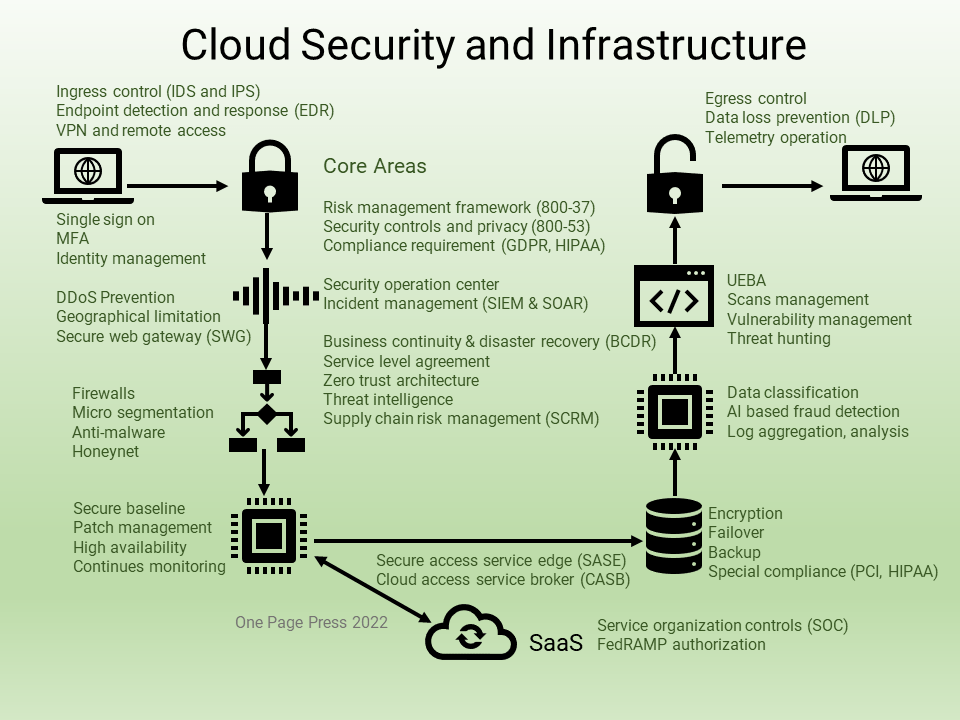
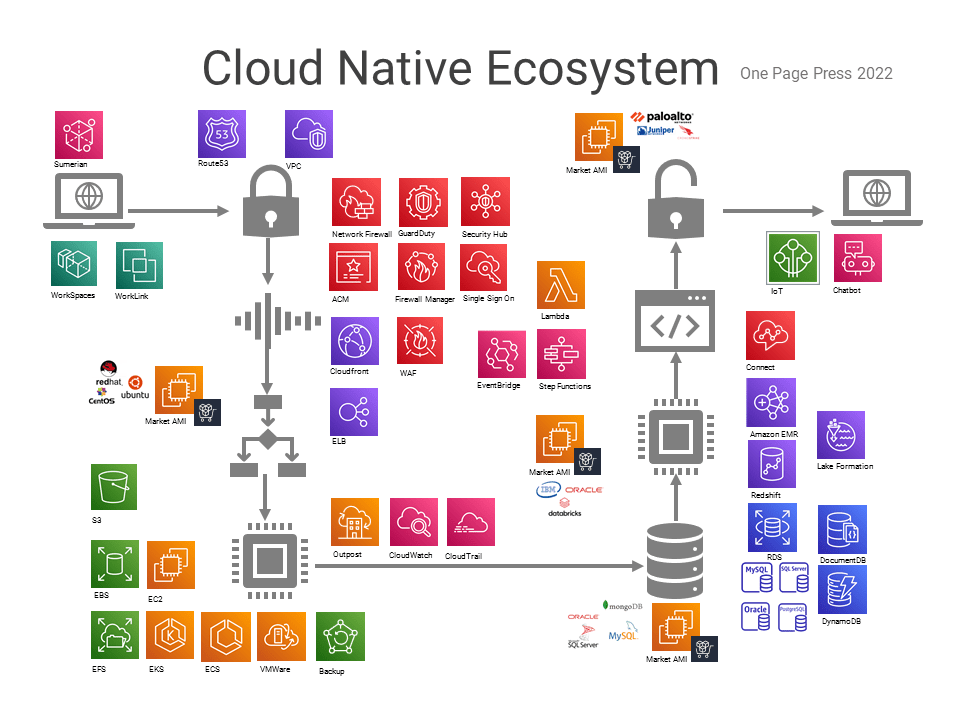
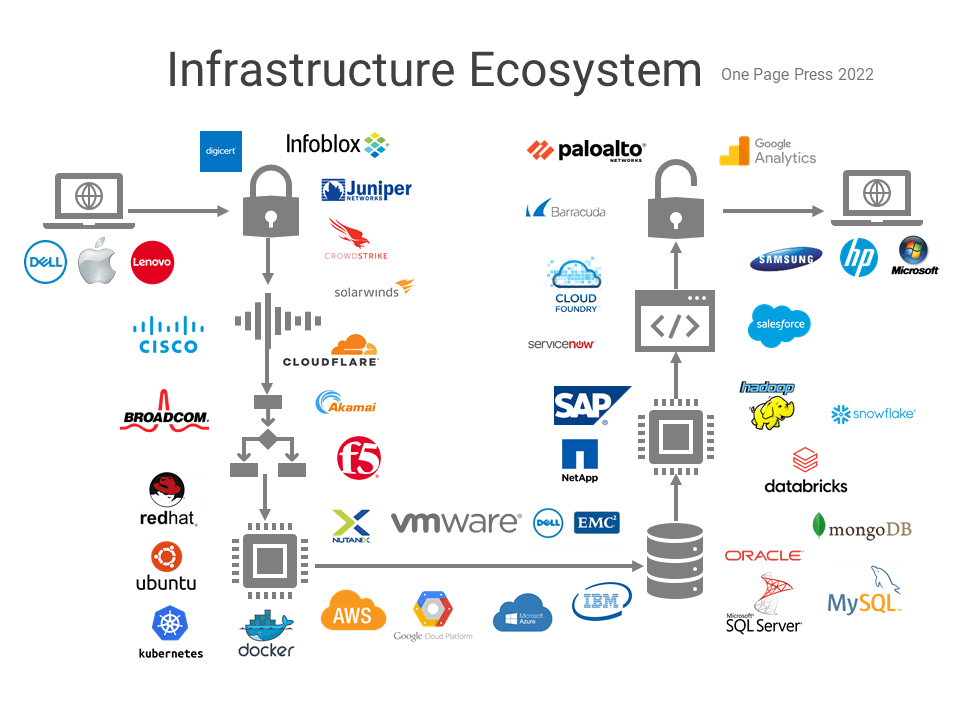
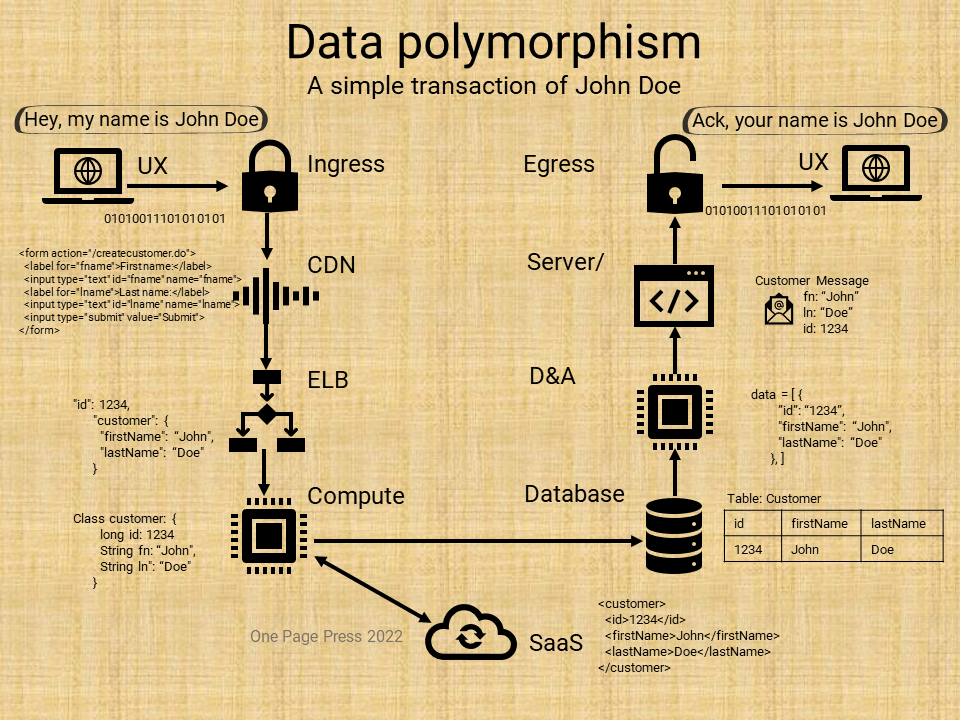
Problems by themselves are fishes. Problem solving is fishing. We will talk about fishing using a simple math problem.
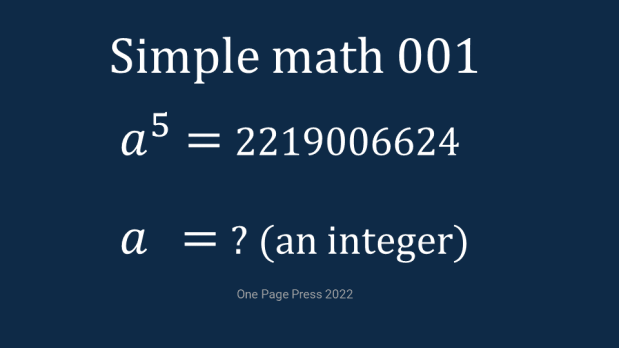



Yes, you can brute force to get the answer on this one. It will take you a while wouldn’t it?
The first approach starts from zoning, meaning first to identify a reasonable zone of upper and lower boundary. 2219006624 is 10 digits, where 105 is 6 and 1005 or 1010 is 11. This is your starting point. Another round of fine tune will land you in the 70 to 80 range.
With an even number ending, you can select from the set of 72, 74, 76, and 78. 76 should be an easy out because power of 6 will always ended with 6, not 4. Either sensitivity to numbers or a brute force with 2 candidates (if the first 2 are not the answer, the 3rd must be the answer) can get your the right answer, 74.
Me, on the other side, went to the second approach. I quickly sensed the uniqueness of a5 where the last digit is always the same as a itself. This means 2219006624 can only be a number ended with 4. The size of 2219006624 can lock the the answer among 94, 84, 74 or 64. This is where either a similar analysis from first approach, or a similar size of brute force can give you the right answer, 74.
There might be 3rd or more approaches. People always have special ways to get the right answer. Again, this post is not surrounded on math, but strategy and thought process. On my last slide, I summarized a few lessons learned:
- Layout a strategy first. No matter what kind of problem you are facing, having an early and well defined strategy is necessary. The effectiveness of the strategy will decide the outcome.
- Break the problem into components and steps. Divide and conquer. Those steps can be sequential or concurrent, those components can be inclusive or independent, but componentization is a common method to deal with a challenge at large scale.
- Execution. Plan does not solve problems itself, but guide the “how to”. It requires muscles and wills to get the job done. Good execution is always needed.
- Diversity. All roads lead to Rome. Different people are sensitive or well trained in different skills areas. They approach the same problem from different angles and can be effective in different ways. Combine them together, the team can perform at higher level.
This is common we need a similar problem solving approach in technology world. Zoning in is useful technique to narrow down options, root causes, or methods. Pattern (the powerful part of 2nd approach) is effective weapon in pinpointing “the thing” at fine grained levels. Use them both, a problem solver can be a sharp shooter.
With more examples coming, I hope this series serve some its purposes on how to solve problems. And the content is useful to you.