Spend the first 1% of energy to reduce the complexity of a problem 10 times. This is what a successful pathfinder does.
Effective problem solving requires methods and precision from experience. Observability can give you clarity and facts, it is not a replacement of the big picture. Let’s see what a big picture might look like:

In my recent blogs, I use simple math to illustrate this pathfinding strategy:
A lesson learned from simple math 001 is zoning in and then pinpointing. It teaches how we do not deal with mega size numbers, but come to reduced size. In the 2nd and more advanced solutions, it lock the end number of correct answer as 4, so it reduce the problem 10 times immediately.
A lesson learned from simple math 003 mentioned a similar approach. In that case, the key of success is by observing the pattern of a number and scale it down 9 times to start. In real life events, when you a facing a hazy, nasty, cloudy, and urgent incident, that zoning in approach is an absolute must.
Today’s technology incident is complicate. It could be anywhere of buggy code, bad data, unexpected traffic, or anything on my maze. A blackout situation is usually easier to trouble shoot than an intermittent problem.
I will explain a few selected labels in brief:
- Eliminate the obvious first. This is the first step of incident intake, where false positive, users errors, client device, client service provider, geolocation and other similar factors to confirmed before the official establishment of an incident. A strong tier one support and procedure can effectively control the intake.
- Expirations usually leads to a dark out situation, so it is your first 1% effort to either eliminate or confirm. They are subscription expiration (unpaid account), certificate expiration, password expiration, support expiration, and contract expiration. This is usually a case of high severity, but easy to fix. Check expiration before everything else.
- Permission can be in many places. It can be a complete deny of service or a partial one, where only a portion of users and resources are blocked, such as identity and access management (IAM) issues. Permission usually leaves strong clues from log, so it is not hard to trace down. Once confirmed, this is also an easy case to restore.
- Cloud services. This means anything cloud service provider owns, from availability zones to access, network, compute, storage and other supporting services. It is unusual to encounter a massive cloud blackout, but there are sparse cases that certain portion of the services are down. The system status page, RSS, and your account support are usually best source of information.
Iterating all items is not needed for a short post. So I will stay on the surface of this discussion and leave more for you to think. Early in One Page Press, there are a few other posts worth your read:

Incident pyramid concept: Do not ignore those minor ones, they might be the start of a major disaster.
Read the full post here:
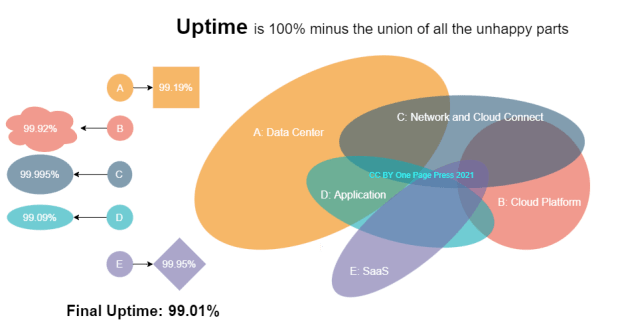
Uptime concept: 100% – Union of all downs. The hybrid architecture today is making more pieces in our IT ecosystem.
Read the full post here.
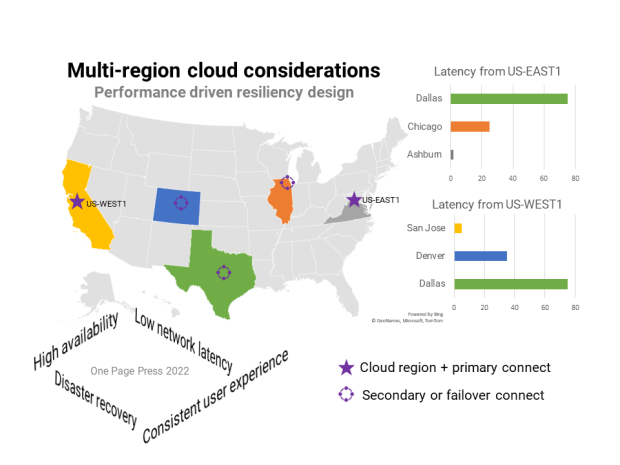
Cloud connect design: Use performance metrics to design for maximum response time.
Read the full post here.
Firefighting in general, such as incident resolution, disaster recovery, cyber forensics, and any kind of truth finding and peace restoring are my favorite part of work. It tests your experience, knowledge, calmness, methodology, judgement, and leadership. It is where result saves, team matures, trust built, and lessons learned.
