Uptime objective is part of a service level agreement (SLA), which defines the terms and performance metrics by a service provider. SLA covers a long list of system characteristics, where uptime is usually the central figure.
Computing is more and more distributed these days. It evolves from monolithic in a physical data center to virtual, to cloud, and to edge. Uptime of a typical system today has five main components. Please also see a more technically drawn in my earlier post: A hybrid cloud architecture
Uptime is: 100% minus union of all incident time, seen from this picture.
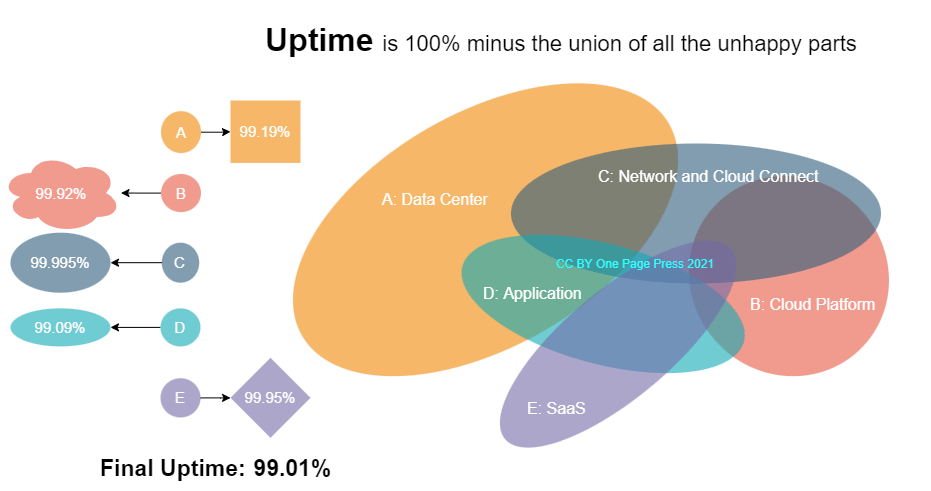
A: Data Center – This is where power outage, flood threat, cooling problem, uncommon human events can come into play. Typical outage from operation are hardware and cable failures, storage and hypervisor problems, virtual and physical machine breakdowns.
B: Network – Network is usually the highest uptime holder in the entire chain. It covers transport services, private link among data centers and corporate offices, and cloud connect. VPN is also part of this service.
C: Cloud platform – This is public cloud, gov cloud, or private cloud. It is composed of cloud services that a provider (AWS, Azure, GCP for example) offers to run your workload, and associated infrastructure. Cloud infrastructure covers hybrid connectivity, organizations and users, accesses, service control and guardrails.
D: Application – This is the biggest wildcard among all. Application can be on premises, in the cloud, or both. Since application is on the top of OSI layer (please check out my earlier post), I has the most variance than any other parts. Bugs, test failures, data quality issues, missing dependencies, lack of coordination, all could lead to a break and fix. Any undetected defects in the security area is usually the worst nightmare of all. Modern day continuous integration continuous delivery (CICD) platform and micro service architecture promote agility of change and improve the application uptime via faster turnaround. However, in my opinion, the best recipe is quality, usually boosted by team, culture, discipline, process, and effective assurance.
E: Software as a service (SaaS) – This is where you choose buy over build. SaaS can be your entire solution, or part of it. SaaS can runs critical workload for your organization, or provide a desired feature. From authentication and authorization, identity management, fee collection, to an AI plug in. SaaS is everywhere.
My main point and example is the actual uptime of a business is total available time (100%) minus the union of all the unhappy parts. It is not an intersection. Unfortunately, outages do not have a rendezvous, to help you reduce the overall downtime.
Therefore, consider followings to increase your overall uptime:
- Network service and network engineering are your top priorities. Digital transaction is data packet moving from one end point to the other. Network is your highway, private way, and shortcuts to the destination.
- SaaS first. Usually SaaS bears much higher SLA than self-build systems. SaaS allows you to pass the SLA requirement to the provider.
- Cloud first. Infrastructure as service (IaaS), platform as a service (PaaS), function as a service (FaaS). Cloud infrastructure performs better than data center.
- Data center modernization. Use software defined and hyper converged infrastructure (HCI) to transform your data center operation. Automation is vital, and start looking at AIOps.
- Application. People consider uptime as an infrastructure challenge. In reality, the most contributing factor is application. At design time, software architecture dictates the underlying infrastructure, a wrong choice is very hard to be mitigated in operation. At run time, early detection, fast rollout (CICD), open technologies, automation and collaboration can help.
- Other transformational ideas. Consider application less, by solving your business problem without an application. Consider artificial intelligence operation, so operation and recovery with less human intervention. Consider least hop and local compute when the use case applies, the more a system depends, the more likely it breaks. That is the whole point of my post: union of all unhappiness.
Leo Tolstoy’s famously said: Happy families are all alike, every unhappy family is unhappy in its own way.
Uptime is a job to connect a chain of families with maximum happiness. You may also get some insight from my post of: The power of the right way
